03 Pandas+Pyecharts | 中国大学综合排名分析可视化大屏(普版+Flask版)
- 可视化系列
- 2025-07-13
- 1411热度
- 1评论
大家好,我是欧K~
软科中国大学排以专业、客观、透明的优势赢得了高等教育领域和社会的广泛关注和认可,本期将利用Python对我国最新大学排名和分布情况进行一番研究,希望对大家有所帮助,如有疑问或者需要改进的地方可以联系小编。
涉及到的内容:
Pandas — 数据处理
Pyecharts — 数据可视化
1. 准备工作
1.1 导入模块
from pyecharts.charts import Map
from pyecharts.charts import Bar
from pyecharts.charts import Pie
from pyecharts import options as opts
import pandas as pd
2. Pandas数据处理
2.1 读取数据
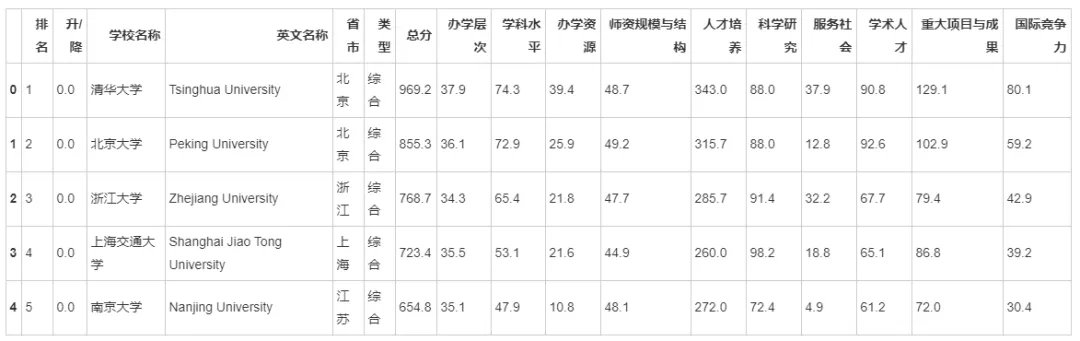
df = pd.read_csv('中国大学综合排名2021.csv', encoding='gb2312')
df.head()
2.2 查看表格数据类型
df.dtypes

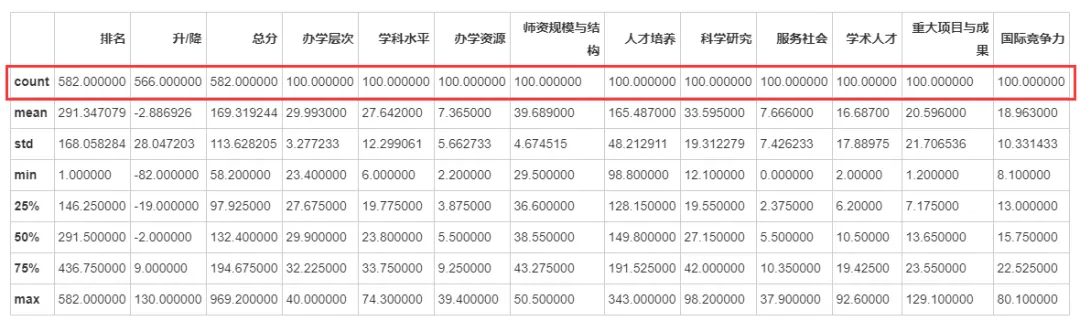
2.3 查看表格数据描述
df.describe()
2.4 查看表格缺失数据
df.isnull().sum()
2.5 填充某一列缺失数据
填充升/降数据,以填充0为例:
df['升/降'].fillna(0, inplace=True)
df.isnull().sum()
2.6 一次性填充所有缺失数据
df.fillna(0, inplace=True)
df.describe()
2.7 统计所有排名未改变的学校
df[df['升/降']== 0]
2.8 统计前50名中排名下降的学校
df.loc[(df['排名']<50) & (df['升/降']<0),:]
2.9 统计各省市大学数量
g = df.groupby('省市')
# 各省份大学数量
df_counts = g.count()['排名']
df0 = df_counts.copy()
df0.sort_values(ascending=False, inplace=True)
2.10 各省市大学平均分排序
df_means0 = g.mean()['总分']
df_means = df_means0.round(2)
df1 = pd.concat([df_counts, df_means], join='outer', axis=1)
df1.columns = ['数量', '平均分']
df1.sort_values(by=['平均分'], ascending=False, inplace=True)
3. Pyecharts可视化
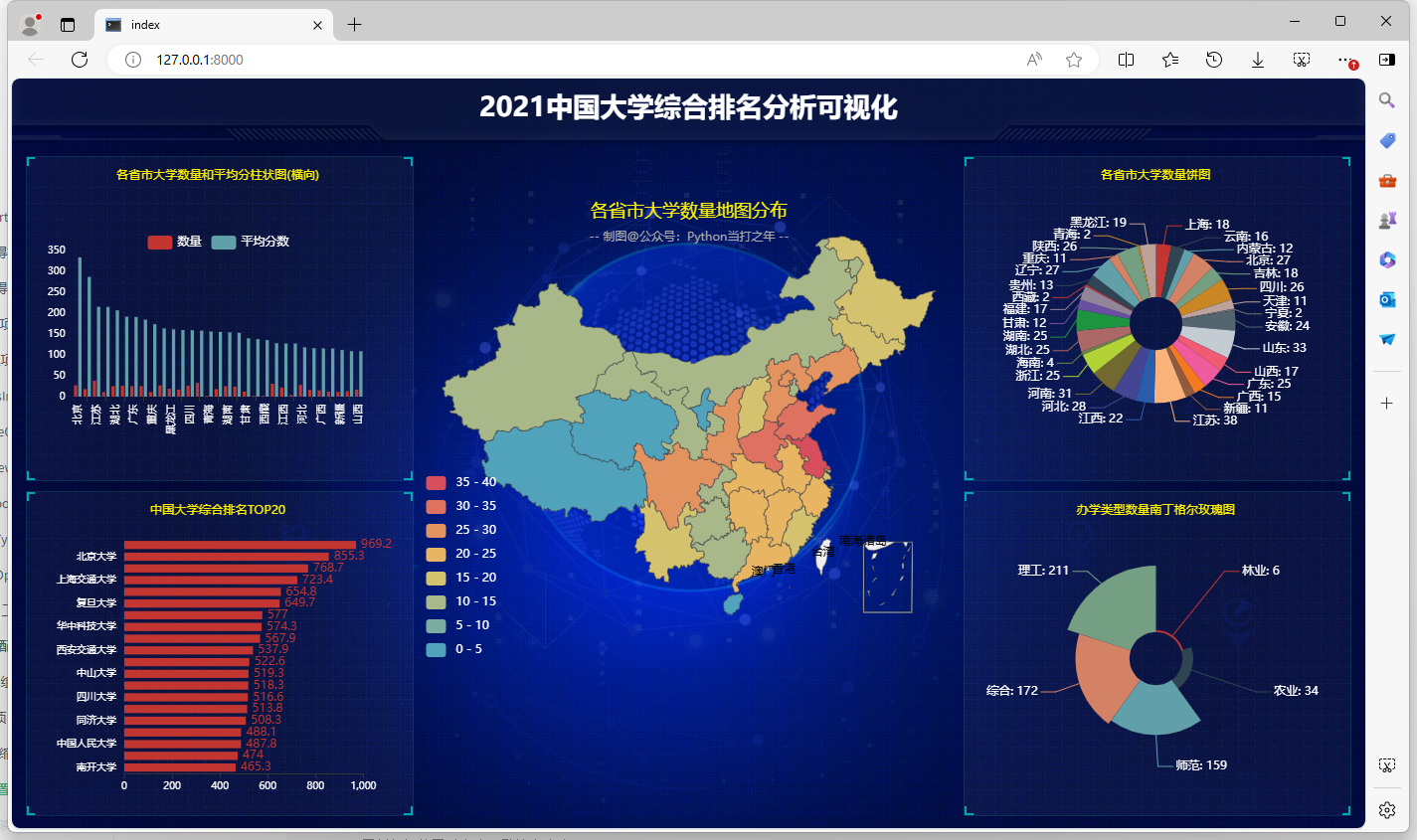
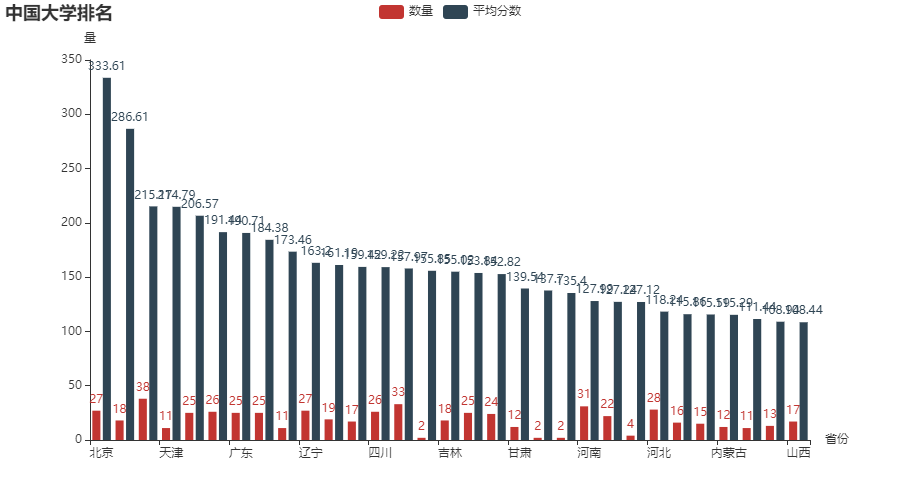
3.1 各省市大学数量和平均分柱状图(横向)
df1.sort_values(by=['平均分'], ascending=False, inplace=True)
d1 = df1.index.tolist()
d2 = df1['数量'].values.tolist()
d3 = df1['平均分'].values.tolist()
bar0 = (
Bar()
.add_xaxis(d1)
.add_yaxis('数量', d2)
.add_yaxis('平均分数', d3)
.set_global_opts(
title_opts=opts.TitleOpts(title='中国大学排名'),
yaxis_opts=opts.AxisOpts(name='量'),
xaxis_opts=opts.AxisOpts(name='省份'),
)
)
bar0.render_notebook()
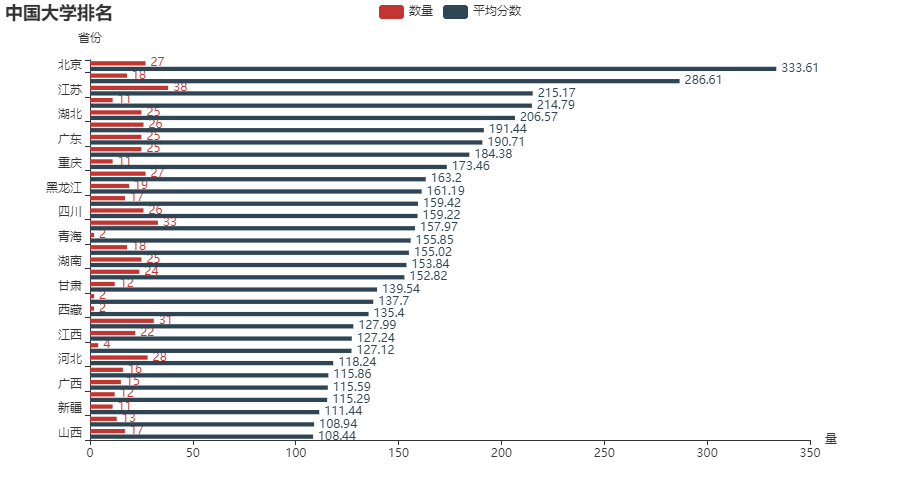
3.2 各省市大学数量和平均分柱状图(纵向)
df1.sort_values(by=['平均分'], inplace=True)
d1 = df1.index.tolist()
d2 = df1['数量'].values.tolist()
d3 = df1['平均分'].values.tolist()
bar1 = (
Bar()
.add_xaxis(d1)
.add_yaxis('数量', d2)
.add_yaxis('平均分数', d3)
.reversal_axis()
.set_series_opts(label_opts=opts.LabelOpts(position='right'))
.set_global_opts(
title_opts=opts.TitleOpts(title='中国大学排名'),
yaxis_opts=opts.AxisOpts(name='省份'),
xaxis_opts=opts.AxisOpts(name='量'),
)
)
bar1.render_notebook()
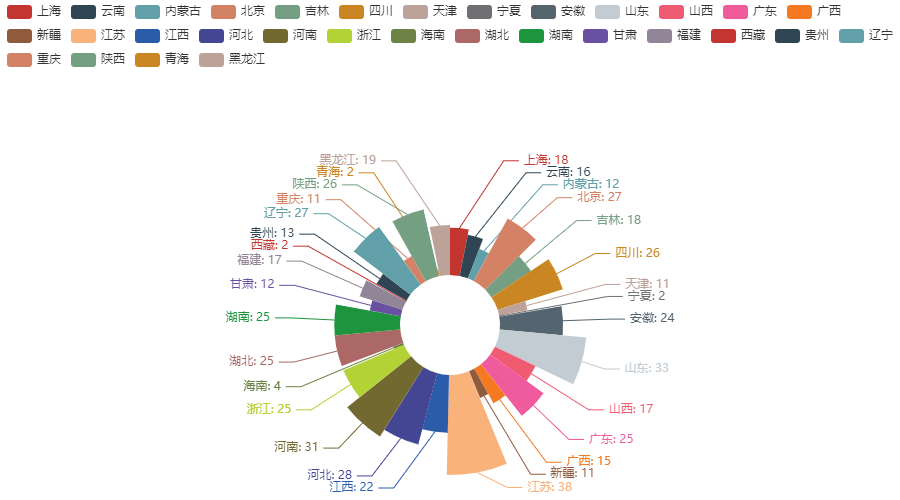
3.3 各省市大学数量玫瑰图
name = df_counts.index.tolist()
count = df_counts.values.tolist()
c0 = (
Pie()
.add(
'',
[list(z) for z in zip(name, count)],
radius=['20%', '60%'],
center=['50%', '65%'],
rosetype="radius",
label_opts=opts.LabelOpts(is_show=False),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter='{b}: {c}'))
)
c0.render_notebook()
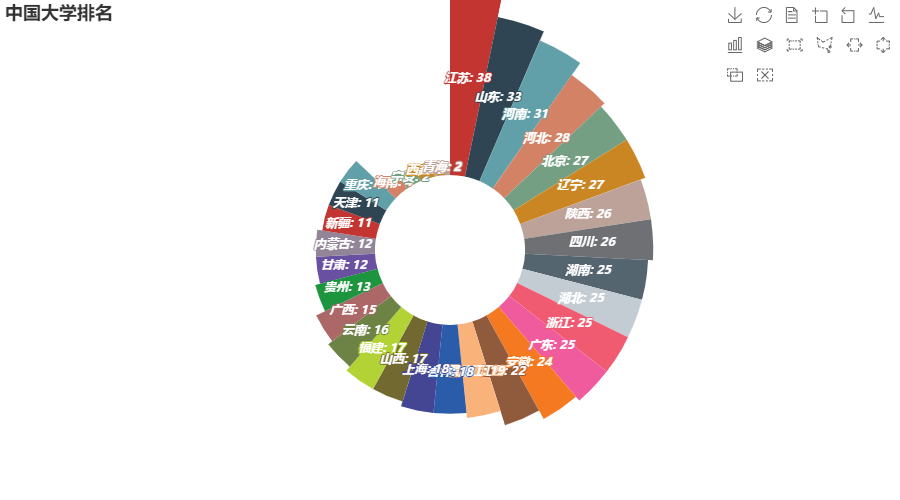
3.4 各省市大学数量南丁格尔玫瑰图
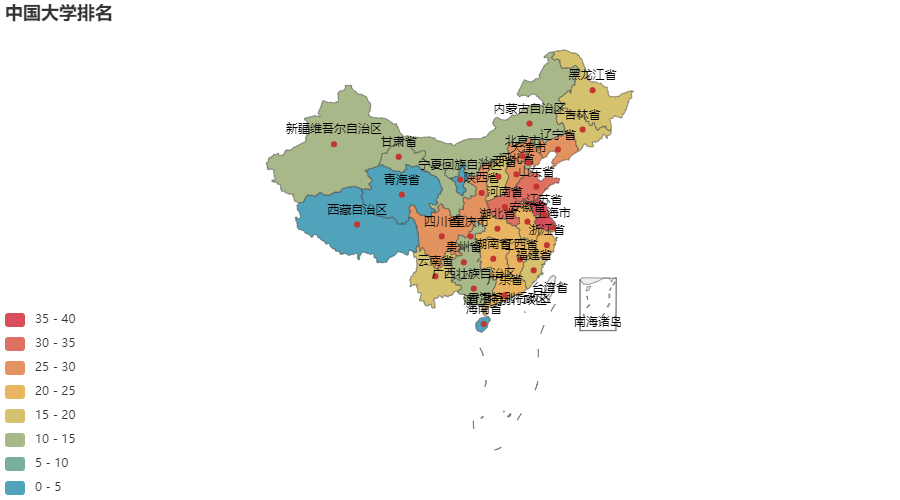
3.5 各省市大学数量地图分布
name = df0.index.tolist()
count = df0.values.tolist()
m = (
Map()
.add('', [list(z) for z in zip(name, count)], 'china')
.set_global_opts(
title_opts=opts.TitleOpts(title='中国大学排名'),
visualmap_opts=opts.VisualMapOpts(max_=40, split_number=8, is_piecewise=True),
)
)
m.render_notebook()
4. 总结
- 大学数量较多的省市:江苏、山东、河南、河北、北京、辽宁 、陕西、四川 、广东 、湖南 、湖北、浙江等地(只看学校数量),后期探索可根据学校排名
排名前20的大学较前一年的波动较小(这也符合常理,毕竟前几的学校都是多年沉淀下来的) - 西部地区大学数量较少
- 本数据集不包含港、澳、台大学(网站未统计)
- 其他...
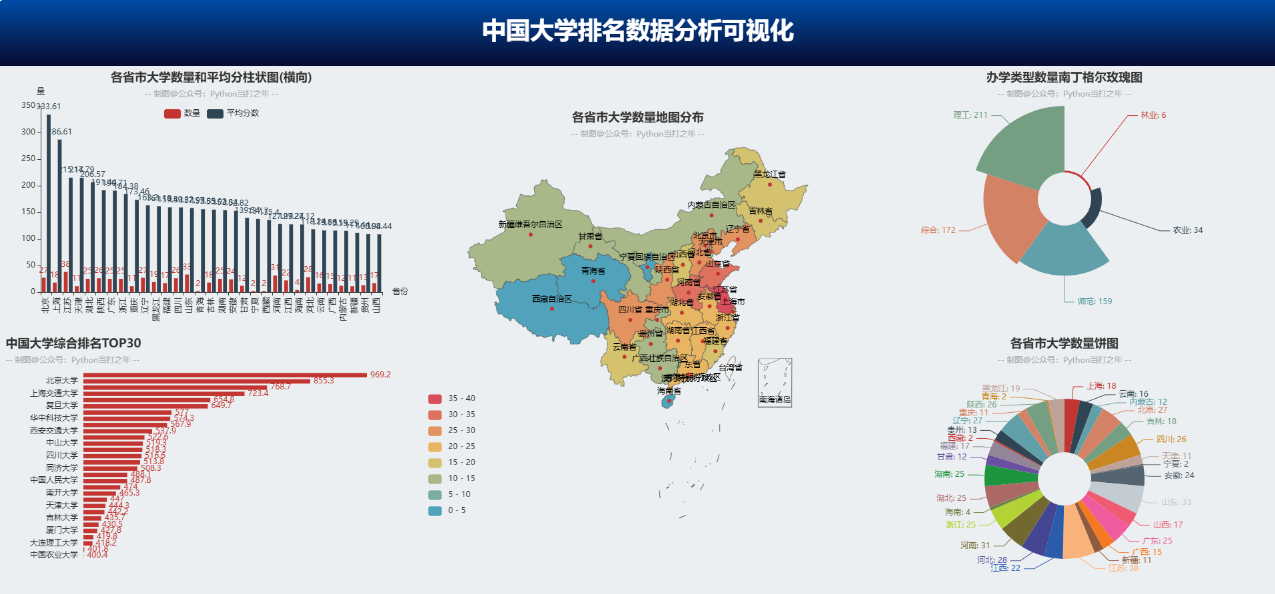
5. 可视化大屏(普版)
6. 可视化大屏(flask版)