32 爬虫 | Python爬取软科中国大学排名
- 爬虫系列
- 2025-07-16
- 1475热度
- 1评论
大家好,我是欧K~
之前分享过一期软科中国大学排名的爬虫分析:爬虫 | Python搞定软科中国大学排名,这里附上全部代码,希望对你有所帮助,所有内容仅供参考,不做他用。
以下是具体分析:
目标网址(软科排名):
https://www.shanghairanking.cn/rankings/bcur/2023
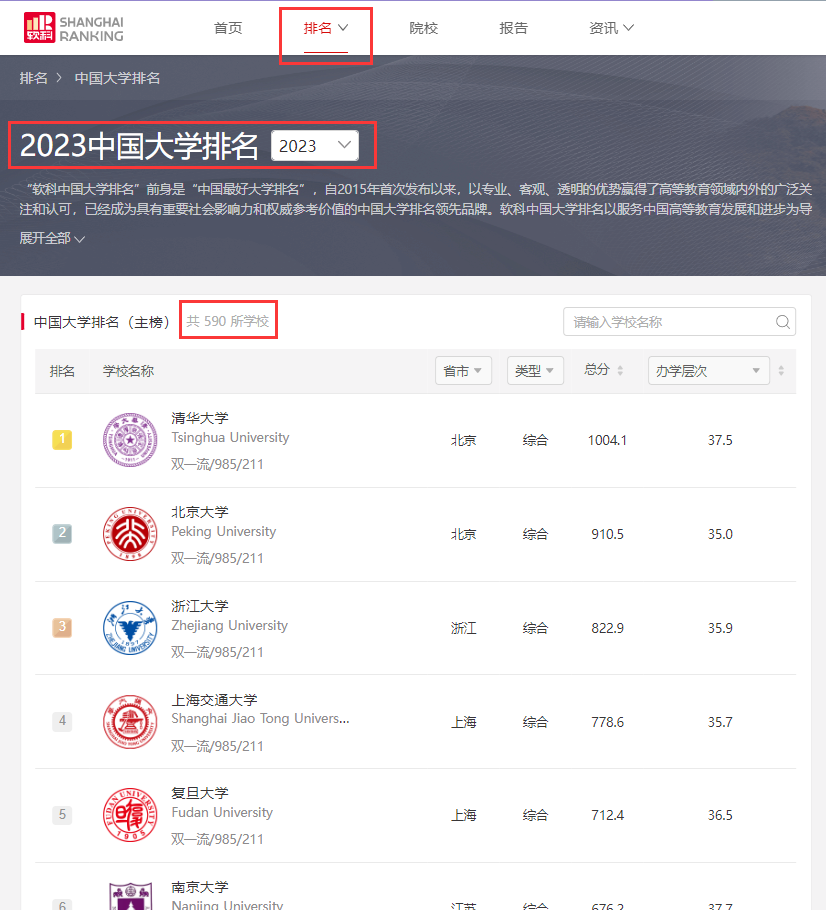
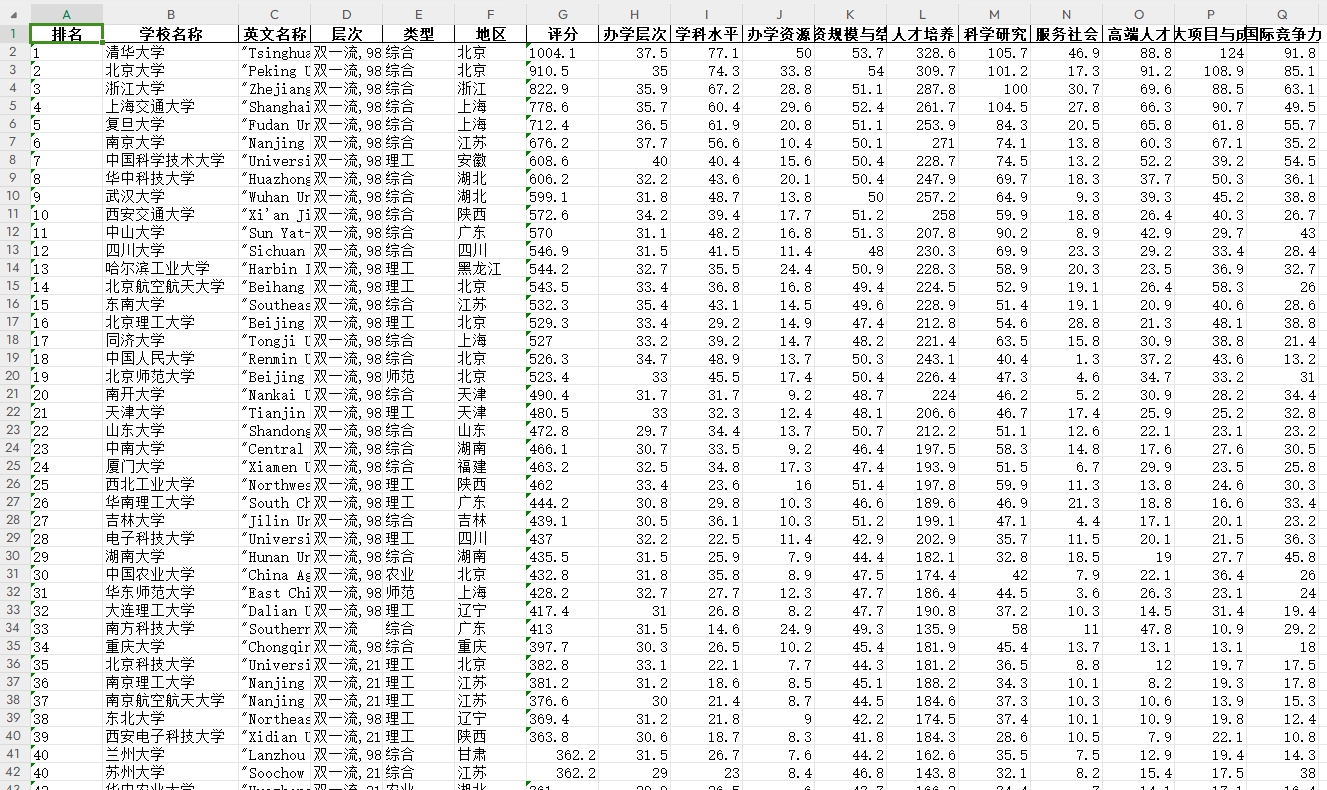
可以看到2023年中国大学排名一共有590所学校。
1. 网页分析
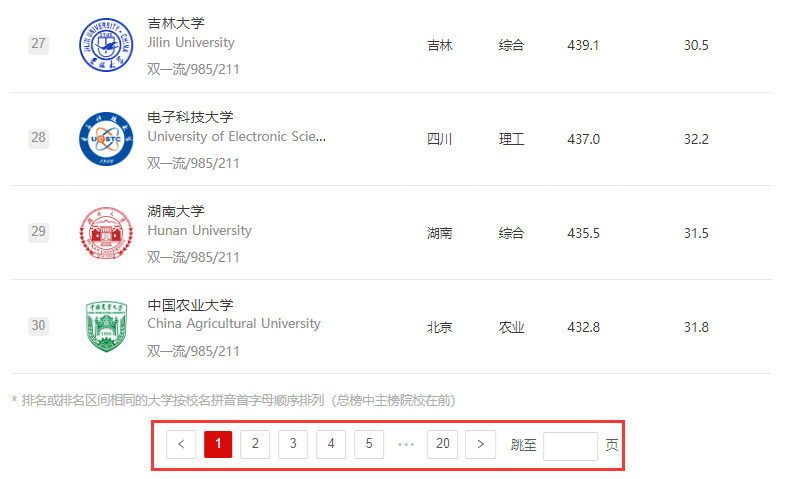
每页30所学校信息,共20页。
点击翻页,发现网址没有发生变化,说明该页面信息应该是动态加载的方式展示的,所以无法通过 get 传参的方式来切换网页进行爬取。
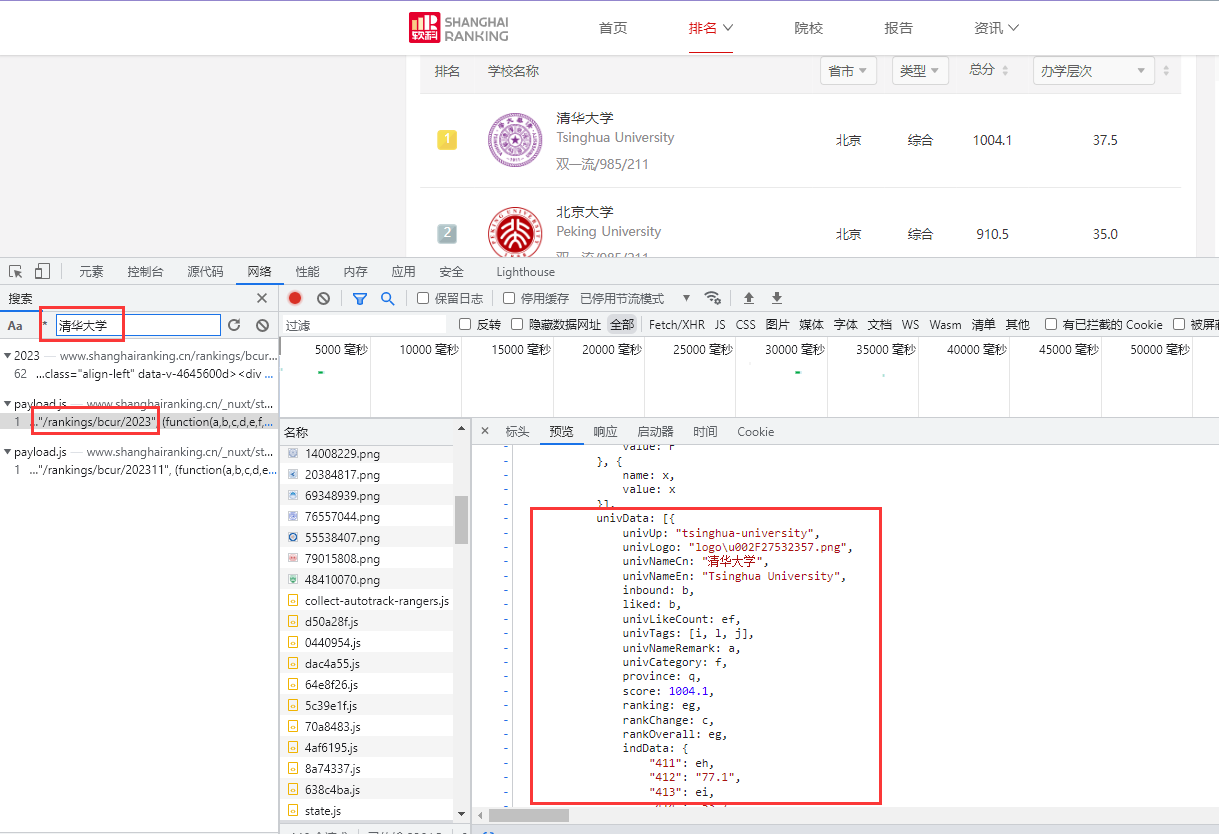
接下来,按 F12 或者右键选择审查元素,搜索一下清华大学查看网页结构:
可以看到信息在一个 payload.js 的文件里,继续查看可以发现这里有590所学校的所有信息,说明网页显示的内容是通过 javascript 解析这个文件动态加载进去的,那么我们只要解析这个文件就可以了。
看一下这个文件:

确定学校的信息的确在这个文件里。
2. 解析js文件
查看学校的具体字段信息:
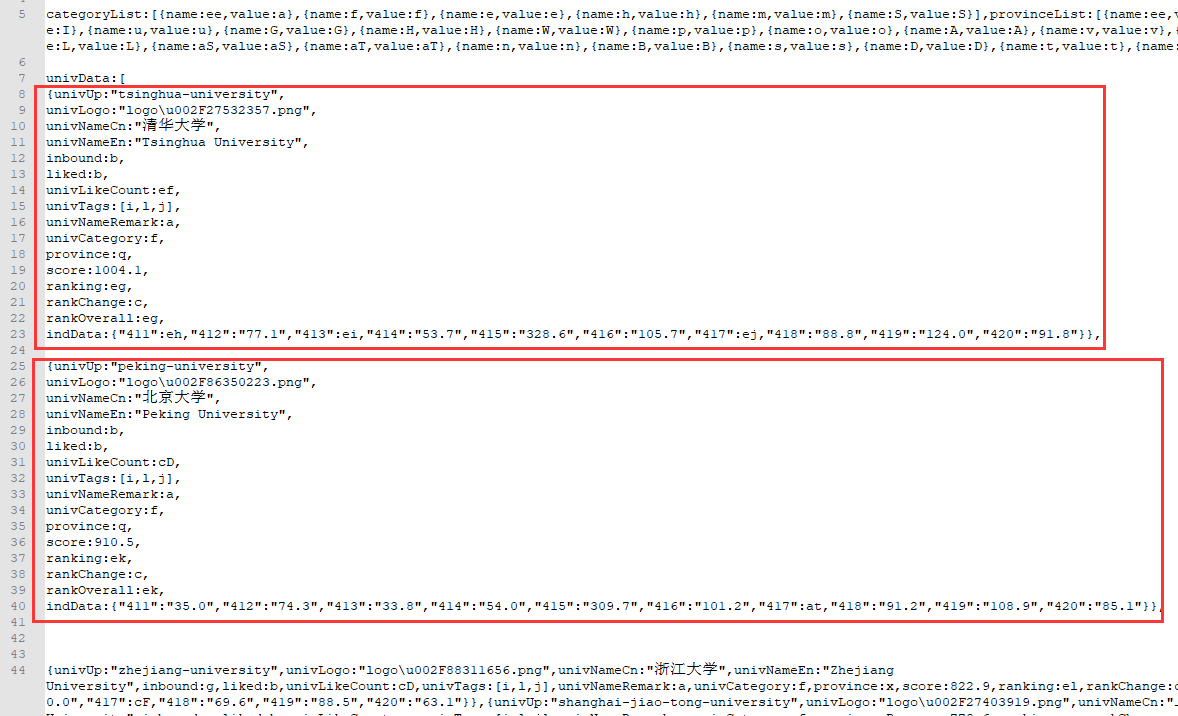
文件内容格式不规则,里面既有类似 json 格式也有 JavaScript 的语法,所以不能直接用 json 进行解析,这里我们使用re正则提取:
datas = re.findall('\{(univUp.*?\})\}',js_str,re.S)
re_compair = r'.*univLogo:"(.*)",univNameCn:"(.*)",univNameEn:(.*?),.*univTags:(.*],?),.*univCategory:(.*),province:(.*),score:(.*),ranking:(.*?),.*indData:{"411":(.*),"412":(.*),"413":(.*),"414":(.*),"415":(.*),"416":(.*),"417":(.*),"418":(.*),"419":(.*),"420":(.*)}'
all_datas = []
for one_data in datas:
d_tmp = re.findall(re_compair,one_data,re.S)
all_datas.append(d_tmp[0])
生成Dataframe:
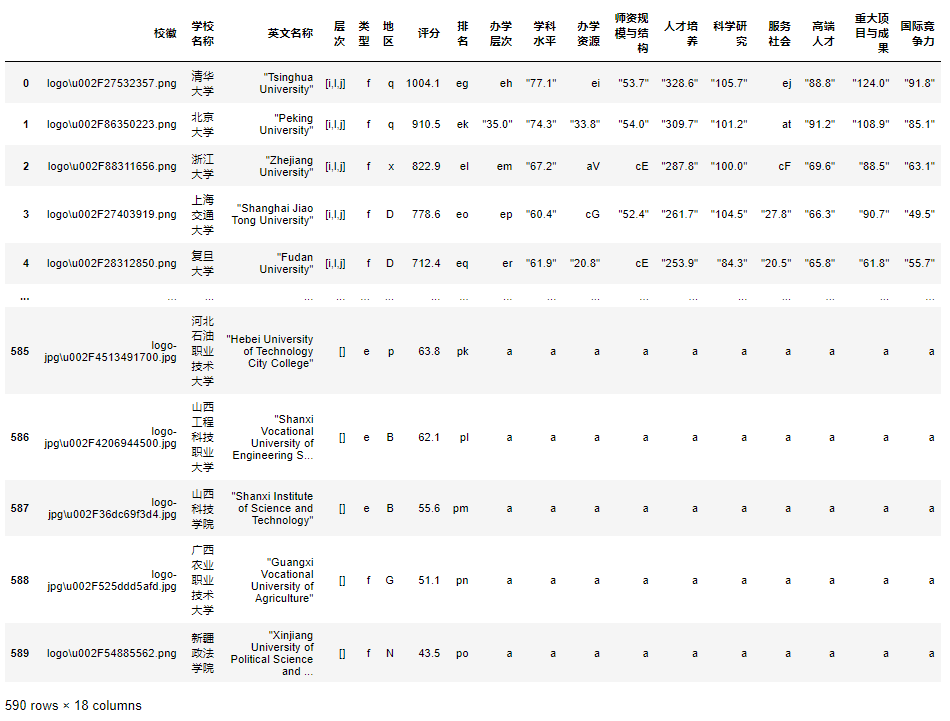
信息是齐全的,但是里面有很多a,f,e,q,[i,l,j],ei,eg,ek...等等字符信息,这些应该是某些信息的替代字符,类似函数中的形参。
继续分析 payload.js 文件,开头部分:
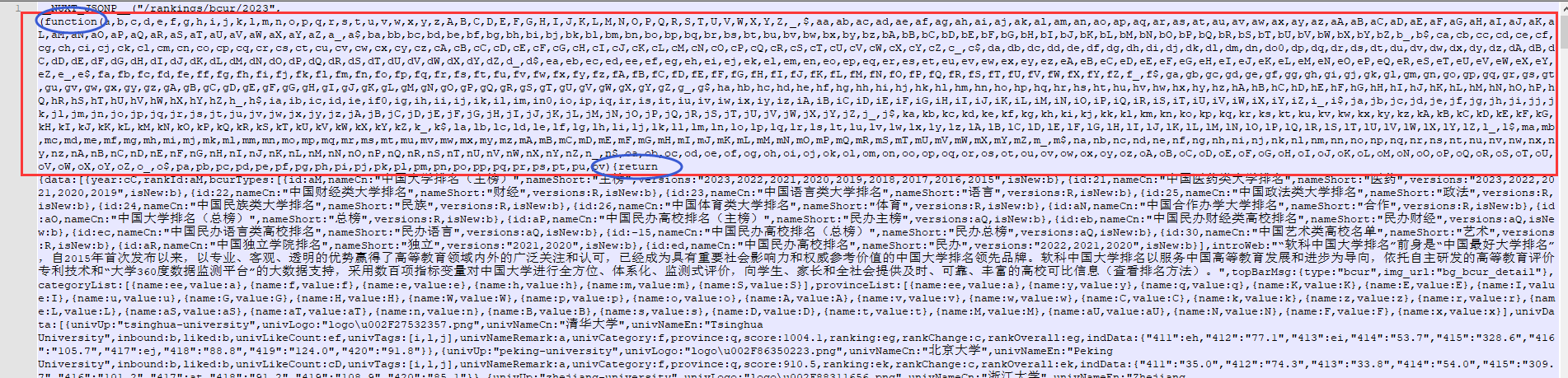
补充知识:
NUXT_JSONP 是 JavaScript 中的一个全局变量,在使用 uxtjs 架时会自动生成,用于在客户端染(CSR)模式下获取服务器端染(SSR) 的数据。在 Nuxt.is 的客户端渲染模式下NUXT_JSONP变量的值是一个函数,用于将服务器端染的数据注入到客户端渲染的页面中。这个函数的参数是服务器端渲染的数据,返回值是将这些数据注入到页面中的代码。因此,__NUXT_JSONP__变量的类型是一个函数。
可以看出来function和return就是内层函数(这里存在函数嵌套)及其返回值,那么(a,b,c,d...ps,pt,pu,pv)就是函数的参数。
结尾部分:
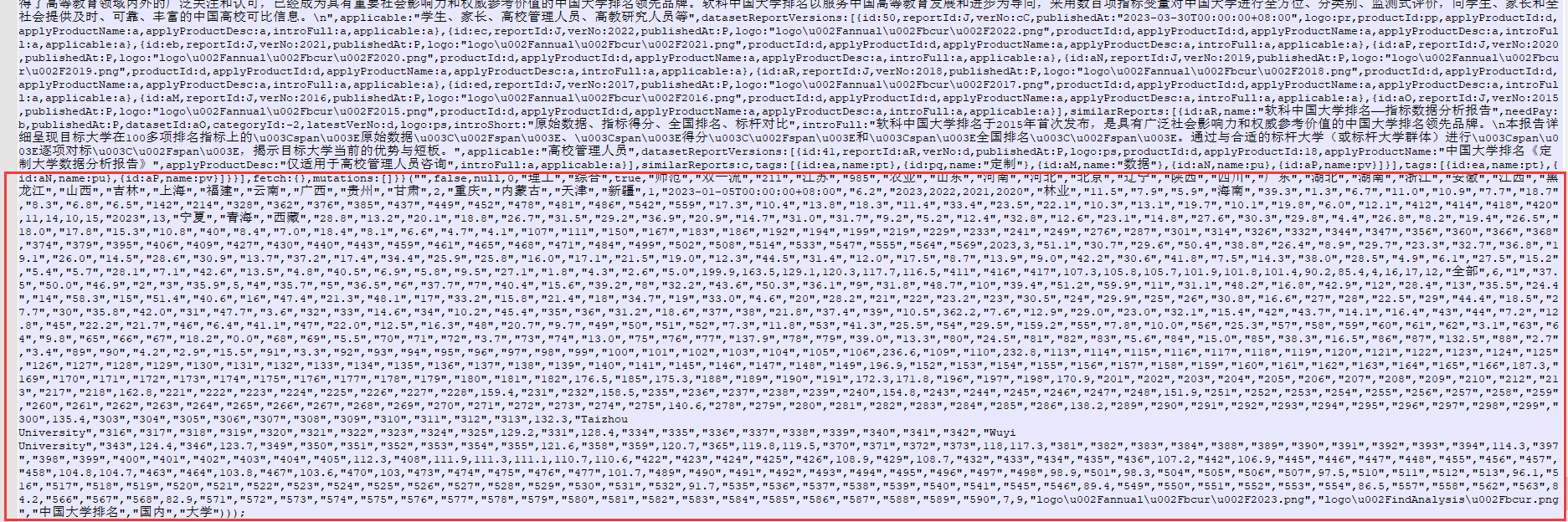
这里就是外层函数的参数,仔细对比会发现外层函数的参数其实和上面内层函数的参数是一一对应的,那么做个字典映射就可以了。

3. 变量替换
获取实际值:
def get(one_data,dd,dic_tmp):
dd = re.findall(re_compair,one_data,re.S)
data_tmp = []
for key in dd:
if key in keys:
key = dic_tmp[key]
elif ']' in key:
key_str = []
key = key.replace('[','').replace(']','').split(',')
if 'i' in key or 'l' in key or 'j' in key:
for kk in key:
key_str.append(dic_tmp[kk])
key = ','.join(key_str)
data_tmp.append(key)
return data_tmpa
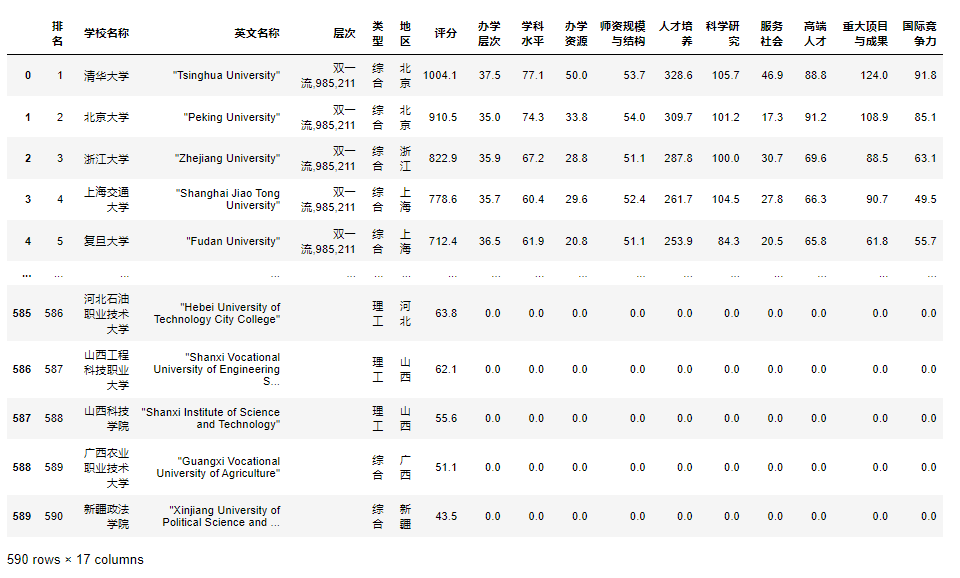
保存表格数据: