37 爬虫 | Python爬取胡润百富榜数据
- 爬虫系列
- 2025-07-16
- 1237热度
- 1评论
大家好,我是欧K~
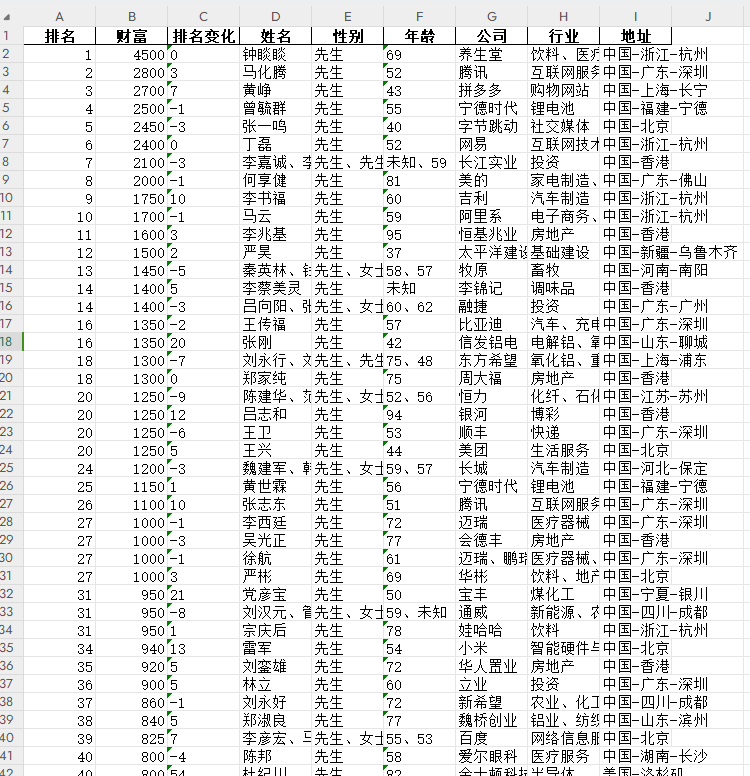
本期给大家分享一下如何用python爬取胡润百富榜数据,包含排名、财富、排名变化、姓名、性别、年龄、公司、行业、地址等信息,希望对大家有所帮助,如有疑问或者需要改进的地方可以联系小编。
可视化部分见:
【35 Pandas+Pyecharts | 2023年胡润百富榜数据分析可视化】
所有内容仅供参考,不做他用。
1. 网页分析
目标网址:
https://www.hurun.net
上榜企业家财富计算的截止日期为2023年9月1日:
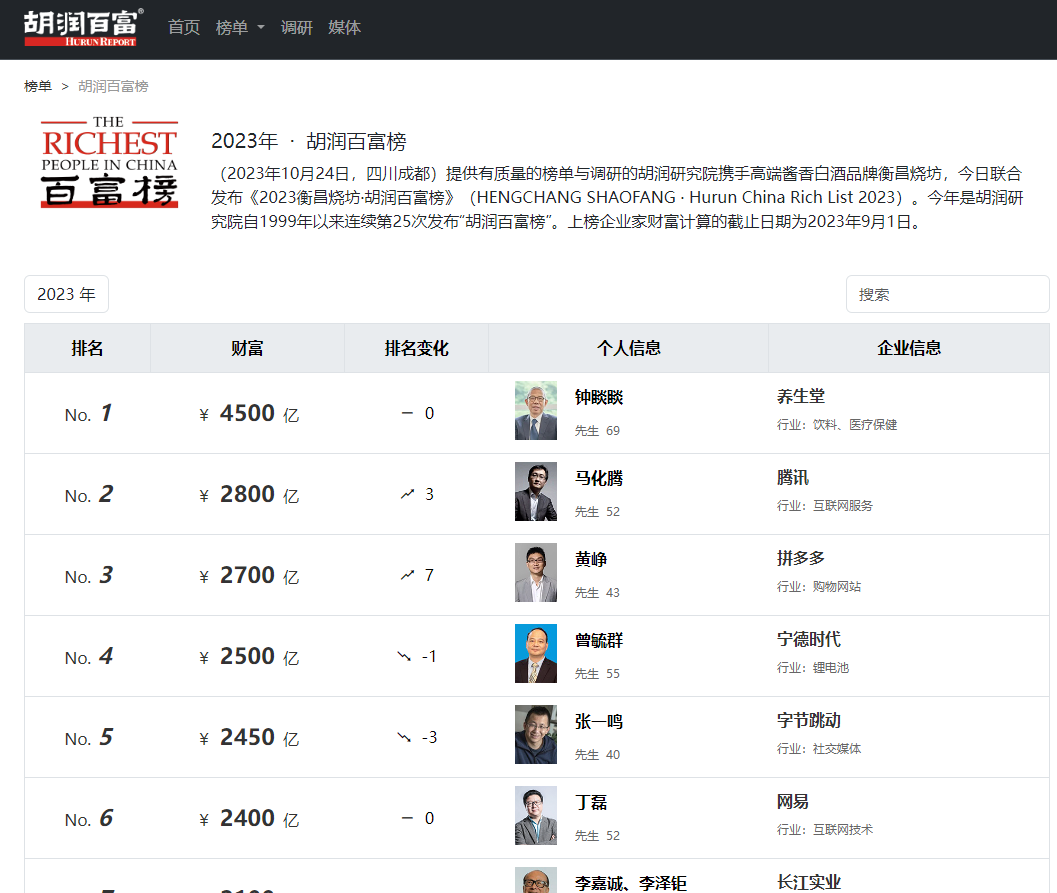
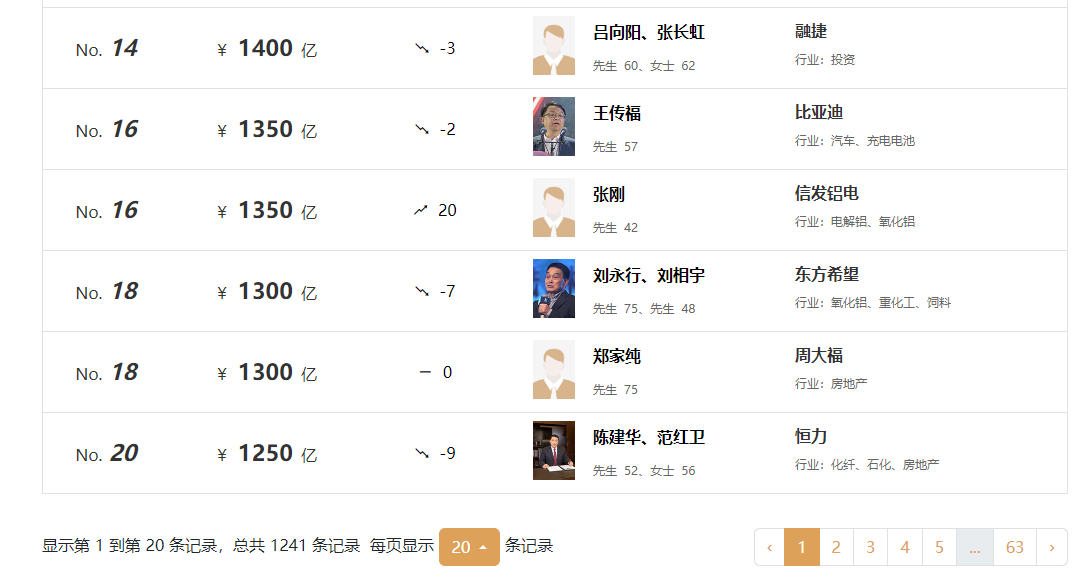
一共63页共1241条数据。
接下来,按 F12 或者右键选择审查元素,以第一个企业信息养生堂为例搜索一下:
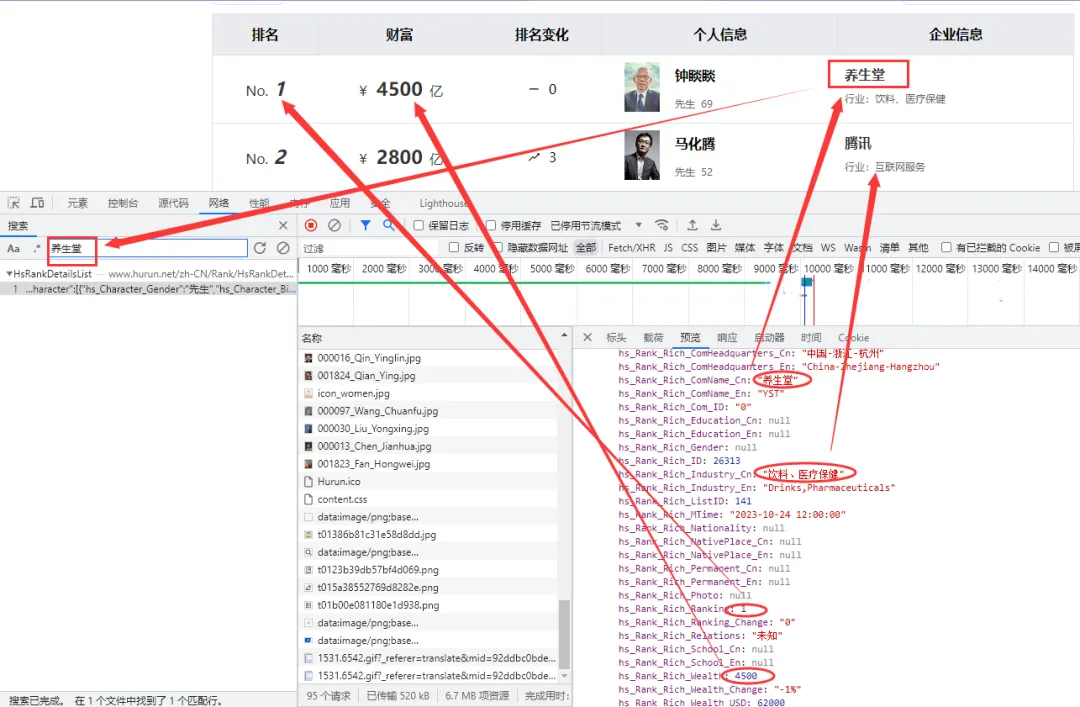
这里我们可以看到相应的各项数据。
继续查看其他元素:
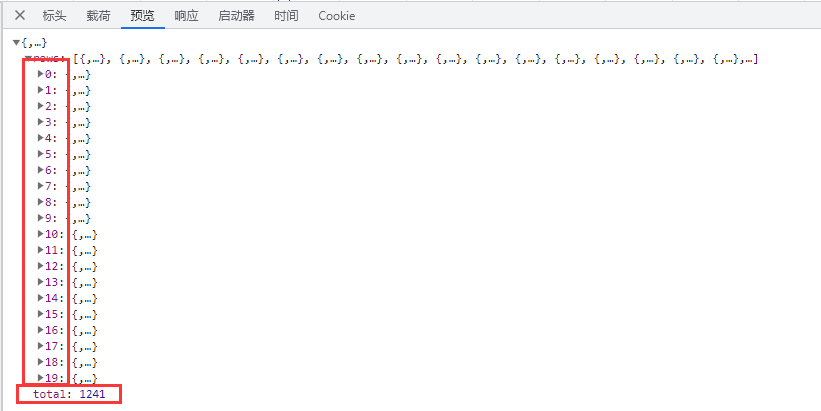
可以看到这里0-19一共20条数据,total为1241也与前面的数据条数对应,基本上确定这也就是我们要提取的数据了。
2. 爬取数据
2.1 导入模块
import time
import requests
import pandas as pd2.2 请求网页数据
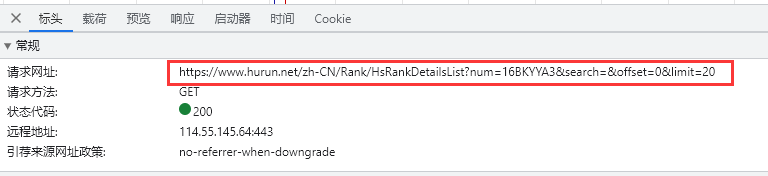
查看网址:
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36',
}
url = 'https://www.hurun.net/zh-CN/Rank/HsRankDetailsList?num=16BKYYA3&search=&offset=20&limit=20'
df = getweibodata(url,headers)2.3 解析数据
# 排名
Ranking = one['hs_Rank_Rich_Ranking']
# 财富
Wealth = one['hs_Rank_Rich_Wealth']
# 排名变化
Ranking_Change = one['hs_Rank_Rich_Ranking_Change']
# 姓名
ChaName_Cn = one['hs_Rank_Rich_ChaName_Cn']
# 性别
Gender_t = []
Genders = one['hs_Character']
for gen in Genders:
gen_one = gen['hs_Character_Gender']
Gender_t.append(gen_one)
Gender = '、'.join(Gender_t)
# 年龄
Age_t = []
for gen in Genders:
age_one = gen['hs_Character_Age']
Age_t.append(age_one)
Age = '、'.join(Age_t)
# 公司
ComName = one['hs_Rank_Rich_ComName_Cn']
# 行业
Industry = one['hs_Rank_Rich_Industry_Cn']
# 地址
ComHeadquarters = one['hs_Rank_Rich_ComHeadquarters_Cn']2.4 保存结果
df = pd.DataFrame(all_data,columns=cols)
df.to_excel('2023年胡润百富榜.xlsx',index=None)