63 爬虫 | Python爬取泡泡玛特微博热搜评论数据
- 爬虫系列
- 2025-07-17
- 1748热度
- 1评论
大家好,我是欧K~
本期给大家分析一下如何爬取微博热搜话题下的评论信息(含二级评论),希望对你有所帮助,所有内容仅供参考,不做他用。
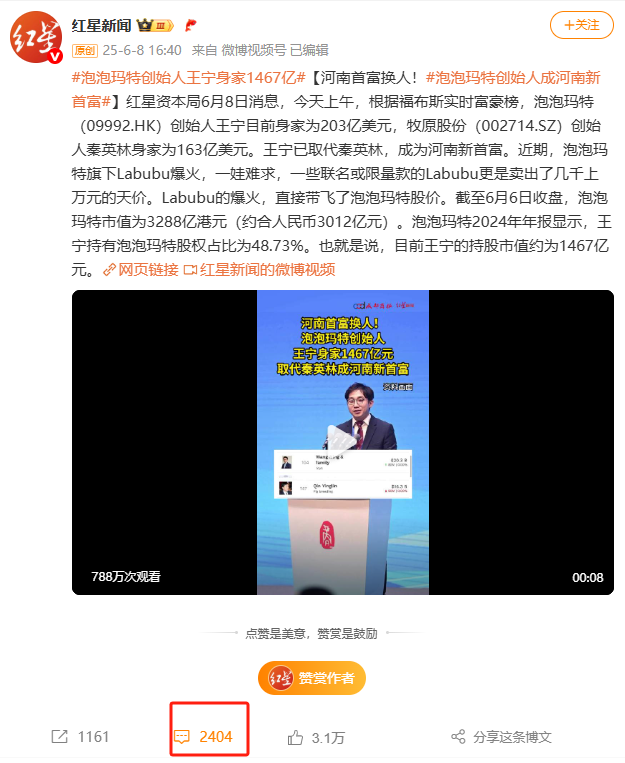
可以看到一共有2404条评论,信息如图所示:
🏳️🌈 1. 网页分析
1.1 一级评论分析
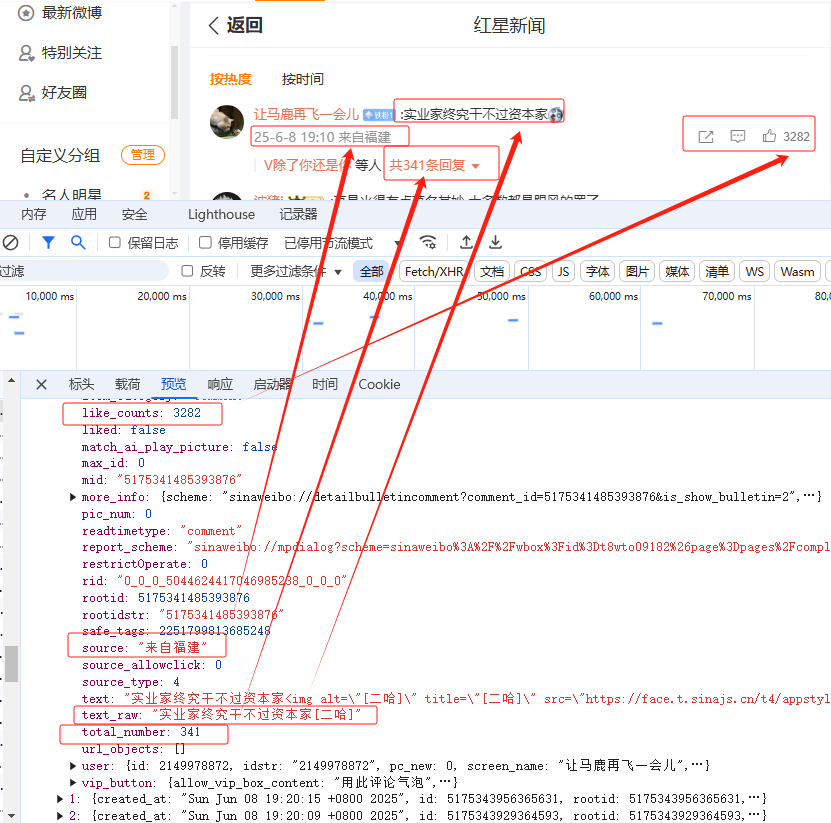
可以看到每条评论的相关信息都在这里,继续查看可以发现每次加载20条一级评论信息:
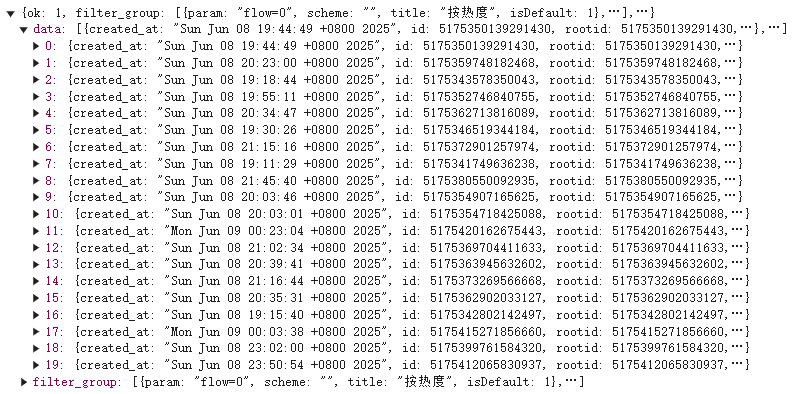
那么我们只要解析这个json格式数据就可以了。以上是一级评论的分析,接下来看二级评论,即评论下的回复评论。
1.2 二级评论分析
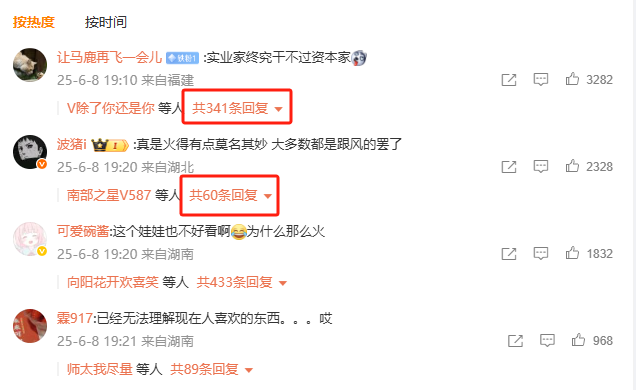
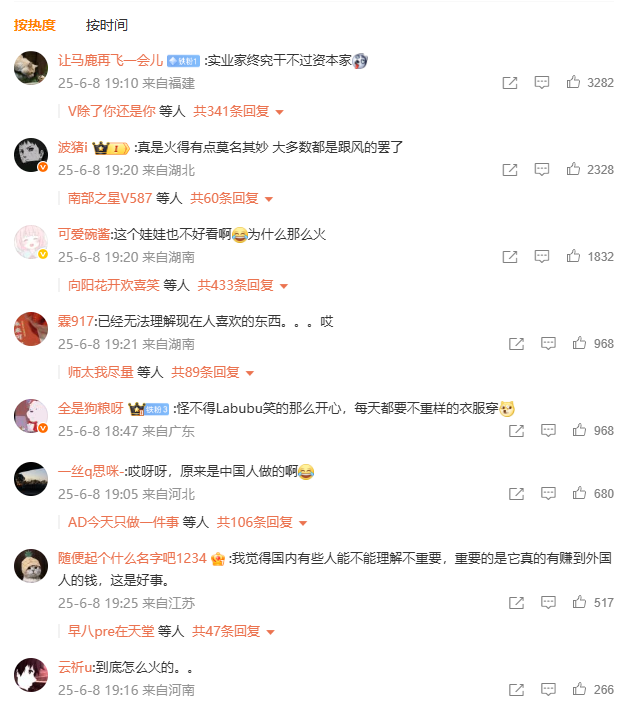
这里需要注意,第二条评论“真是火得有点莫名其妙 大多数都是跟风的罢了”下的回复评论,如下图:
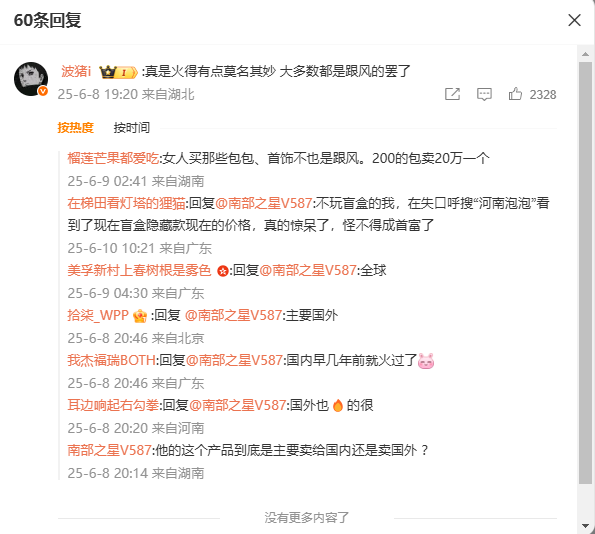
可以看到,网页显示有60条回复评论,但是打开后发现只有7条,其实第一条评论的回复评论也不足341条,所以最终爬取的评论数据会比显示的评论数据条数少的多!
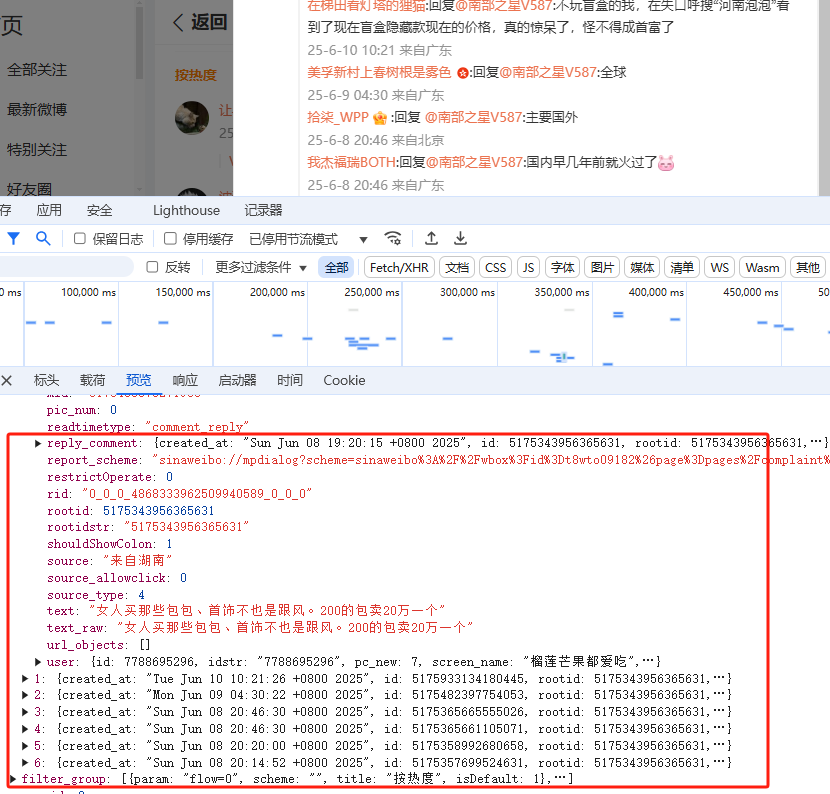
二级评论的网页结构和一级评论类似,这里不再过多赘述。
🏳️🌈 2. 数据爬取
爬取首页评论,计算爬取最大页数,根据每页20条计算最大页数,实际运行页数比这个少(因为显示评论数量和实际评论数量不一致,这个在【1.2 二级评论分析】里有介绍):
uid = '6105713761'
current_count = 0
# 第一页
url = f'https://weibo.com/ajax/statuses/buildComments?flow=0&is_reload=1&id={idd}&is_show_bulletin=2&is_mix=0&count=20&uid={uid}&fetch_level=0&locale=zh-CN'
dp.get(url)
total_number, max_id, count = get_info()
pages = total_number//202.1 一级评论解析
def get_data(result):
comment_info = []
commentList = result['data']
for comment in commentList:
created_at = datetime.strptime(comment['created_at'], "%a %b %d %H:%M:%S %z %Y").strftime("%Y-%m-%d %H:%M:%S")
like_counts = comment['like_counts']
authorName = comment['user']['screen_name']
authorGender = comment['user']['gender']
region = comment['source']
content = comment['text_raw']
oneinfo = [created_at,like_counts,region,content,authorName,authorGender]
comment_info.append(oneinfo)
insert2excel('微博泡泡玛特评论数据.xlsx', comment_info)2.2 二级评论解析
def get_level2(comment):
scheme = comment['more_info']['scheme']
total_number = comment['total_number']
comment_id = scheme.split('&')[0].split('comment_id=')[1]
url_more = f'https://weibo.com/ajax/statuses/buildComments?is_reload=1&id={comment_id}&is_show_bulletin=2&is_mix=1&fetch_level=1&max_id=0&count=20&uid={uid}&locale=zh-CN'
dp.get(url_more)
res = dp.listen.wait(timeout=10)
if res:
iflen(result['data'])>0:
max_id = result['max_id']
count += get_data(result)
for i in range(total_number//20):
url2 = f'https://weibo.com/ajax/statuses/buildComments?flow=0&is_reload=1&id={comment_id}&is_show_bulletin=2&is_mix=1&fetch_level=1&max_id={max_id}&count=20&uid={uid}&locale=zh-CN'
dp.get(url2)
res = dp.listen.wait(timeout=10)
if res:
result = res.response.body
iflen(result['data'])>0:
max_id = result['max_id']
count += get_data(result)
else:
break
print(f'===== 获取 {count} 条次级评论 =====')
2.3 保存数据
def insert2excel(filepath,allinfo):
try:
if not os.path.exists(filepath):
tableTitle = ['时间', '点赞数','地址', '评论内容', '用户名称', '性别']
wb = Workbook()
ws = wb.active
ws.title = 'sheet1'
ws.append(tableTitle)
wb.save(filepath)
time.sleep(3)
wb = load_workbook(filepath)
ws = wb.active
ws.title = 'sheet1'
for info in allinfo:
ws.append(info)
wb.save(filepath)
return True
except:
return False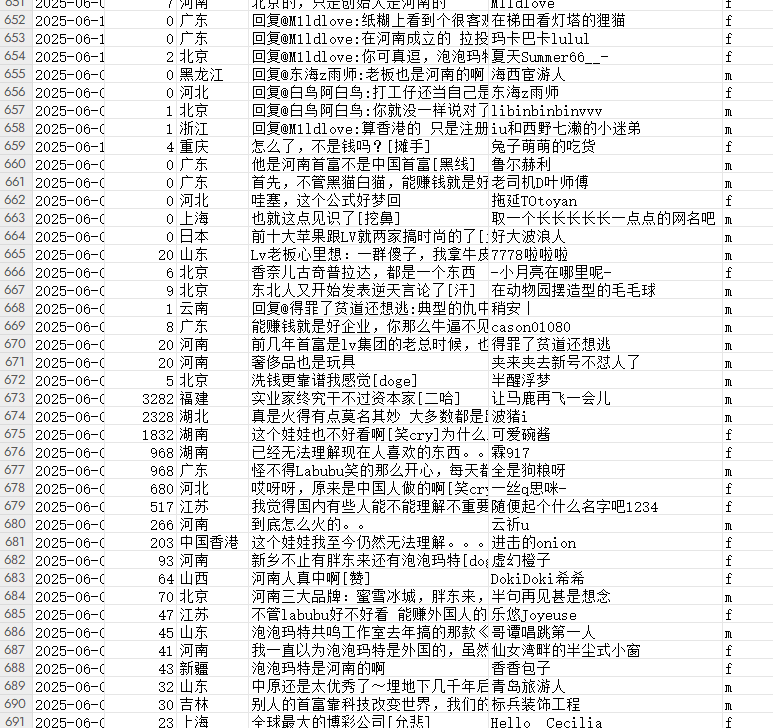
🏳️🌈 3. 更多可视化代码+数据
资源下载 → 源码下载